Acustica I
Dopo aver sviscerato nei minimi (quasi) dettagli la fisiologia della visione, penso sia giunta l'ora di passare ad un nuovo argomento.
Parliamo di acustica e del modo in cui il nostro apparato uditivo analizzi i suoni e ci permetta di discriminare non solo un rumore da un suono, ma suoni diversi o, ancora, stesse note emesse da strumenti diversi.
Cominciamo da qualche nozione fisica sui suoni.
Il suono è un onda che possiede almeno tre caratteristiche fondamentali: intensità, frequenza, timbro.
L'intensità è l'energia associata ad un suono, che ci permette di classificare i suoni in forti e deboli.
La frequenza è il numero di oscillazioni che l'onda sonora compie in un secondo. Ad ogni frequenza corrispondono note diverse. Per esempio il 131 Hz corrisponde al Do che si trova un'ottava al di sotto dell'ottava centrale su una tastiera, 1046 al Do che si trova un'ottava sopra. 440 Hz è una frequenza importante per accordare qualunque strumento e corrisponde ad un La.
Inoltre, come prevedibile da quanto ho appena scritto, a frequenze alte corrispondono suoni acuti, a frequenze basse suoni gravi.
In realtà, i suoni che percepiamo non sono puri, cioè costituiti da una singola frequenza, ma da frequenze diverse, in rapporti ben definiti (le armoniche) e di intensità variabile. Insomma, il Do di un pianoforte non può essere rappresentato da una sinusoide, ma dalla somma di sinusoidi diverse. E il l'onda che rappresenta Do emesso da una chitarra non ha la sstessa forma di quello di un violino o di un sax.
Penso di non aver aggiunto molte informazioni (anzi) alla vostra conoscenza musicale. Magari posso fare meglio con l'anatomia dell'orecchio.
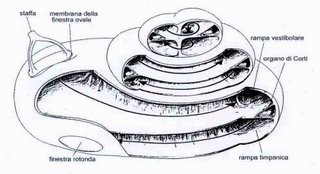
La parte più affascinante del nostro apparato uditivo è la coclea.
Essa è una piccola chiocciola (gli anatomici non hanno molta fantasia), contenuta in una cavità ossea. E' delimitata da una struttura membranosa piuttosto elastica, che, intenrnamente, presenta delle specie di rampe, che la suddividono in tre scale: la timpanica, la media e la vestibolare.
Essa è connessa con la catena di ossicini (incudine, martello e staffa) che sono messi in vibrazione dal timpano.
La scala media contiene del liquido, l'endolinfa, mentre le scale timpanica e vestibolare contengono perilinfa (l'importanza di questa differenza risiede nella diversa composizione ionica dei due liquidi, in cui non entreremo in dettaglio).
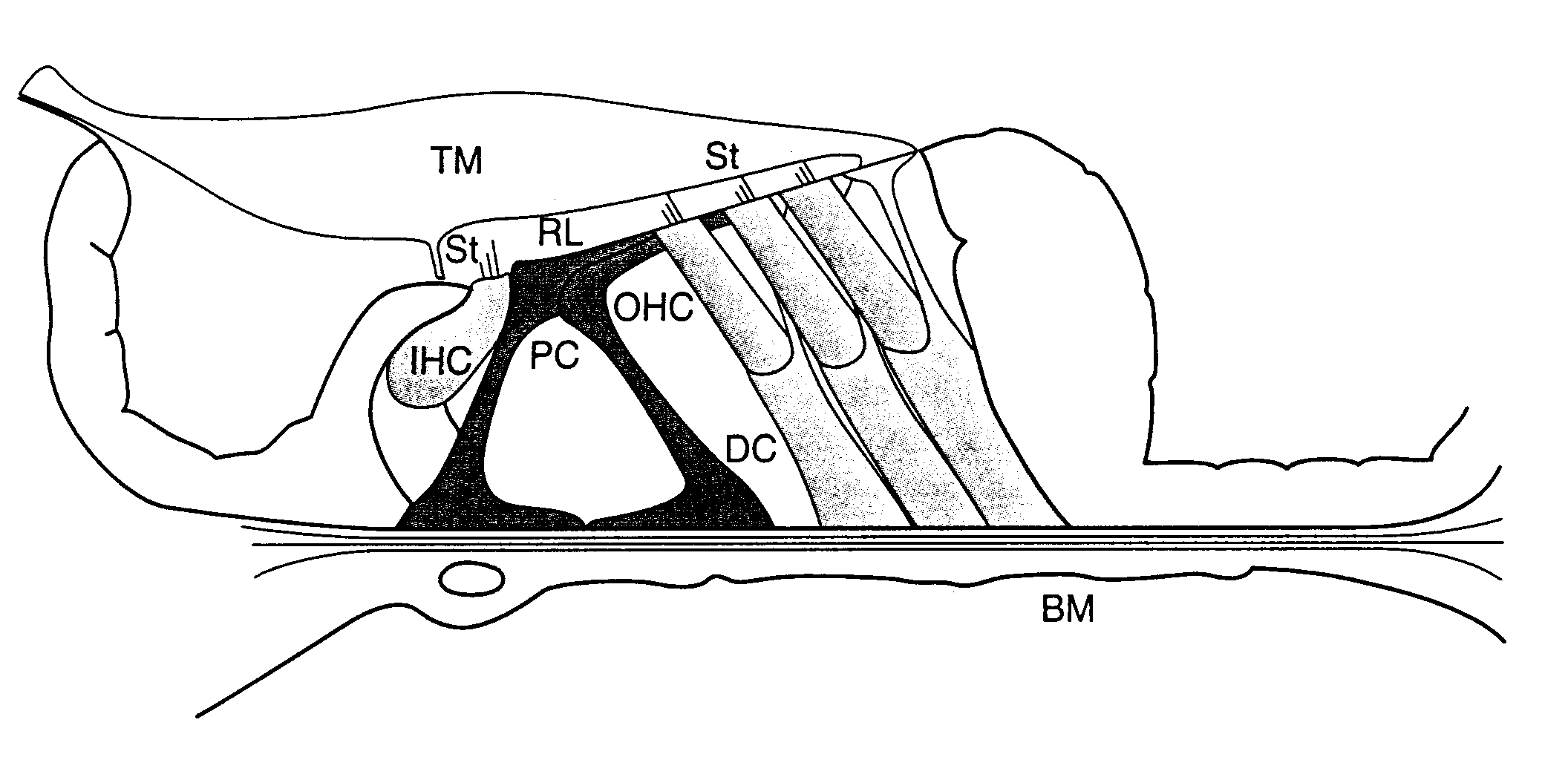
Sulla membrana basilare ci sono delle simpatiche cellule capellute (di potrebbe tradurre così il termine Hairy Cells), che fanno fluire ioni quando deflettono i loro capelli in un senso e limitano l'influsso quando si piegano nel senso opposto. Questo corrisponde rispettivamente ad un aumento ed ad una diminuizione di corrente all'interno delle cellule recettoriali. Tale potenziale graduato (che è tanto più intenso quanto maggiore è la deflessione dei capelli), induce il rilascio di neurotrasmettitori all'interfaccia tra cellule capellute e terminazioni del nervo acustico, che induce l'insorgenza di potenziali d'azione.
Una seconda osservazione che dobbiamo tenere presente è che esistono cellule Inner ed Outer, poi capiremo perchè.

Ora, il potenziale d'azione è un'onda stereotipata, che dura 1 ms, e varia da -80 mV a +120 mV.
Esso è generato, come forse ho già detto, dall'apertura di conduttanze sulla membrana dei neuroni. Ha una forma, un andamento caratteristico, perchè deve essere univoco e riproducibile, chiaro e ben distinto da ogni rumore di fondo, rigenerabile e non attenuabile.
Insomma, in sistema nervoso ha deciso di utilizzare un segnale digitale e non analogico per essere certo che le informazioni non si eprdano e non si confondano. Questo, ovviamente, a scapito di un alfabeto complesso e modulabile. Un po' come usare un lettore mp3 invece dei dischi in vinile.
Dopo questo preambolo un po' complesso, arriviamo al punto.
Se abbiamo un alfabeto semplice, digitale, possiamo solo codificare poche informazioni. In particolare, utilizzando un potenziale stereotipato,l'unica cosa che le cellule possono fare è variare la frequnza di spiking e neanche di molto (c'è un limite massimo di scarica, che corrisponde alla frequenza di 200Hz).
Il problema è il seguene: come possiamo codificare 3 informazioni in questo modo?
E, inoltre, come possiamo coprire tutta la gamma delle informazioni che giungono alla coclea?
Dunque, il nostro orecchio ha deciso di connettere ogni cellula a più terminazioni nervose (10 per ogni Inner).
Per frequenze tra 20 e 200 Hz, le cellule capellute di deflettono con frequenza analoga alla frequenza dell'onda, da una parte e dall'altra, alternativamente. A seconda dell'intensità dell'onda la deflessione sarà più o meno importante e il flusso di ioni più o meno ingente. Il potenziale graduato nelle cellule capellute indurrà variazioni di corrente tanto più grandi quanto più la deflessione è grande.
Alcune delle terminazioni nervose connesse con le cellule capellute spareranno con frequnza identica a quella delle hairy cells, altre con frequenza tanto maggiore quanto più intenso è il potenziale graduato.
Ma se il suono non è puro?
L'orecchio ha elaborato in parallelo al meccanismo appena descritto, che può essere definito time code, un place code.
In sostanza, la coclea funziona come un insieme di filtri, un analizzatore di Fourier, che scompone qualunque onda in un insieme di suoni puri di frequenza definita.
Frequenze diverse raggingono punti diversi della coclea, deformandone la membrana. Insomma, ciascun punto subisce una deformazione massima per una determinata frequenza, con i suoni acuti che deformano massimamente la porzione basale, i suoni gravi quella apicale.
Questo permette di avvertire la differenza tra un pianoforte ed una chitarra, per frequenze fino a 200 Hz.
E per frequenze superiori?
Qui entrano in gioco le cellule outer, che amplificano la deformazione della membrana basale per frequenze specifiche, con un meccanismo diverso da quello delle inner, che permette loro di contrarsi a frequnze elevatissime (sono delle specie di piccole molle che si allungano e si accorsiano). Anche le outer sono connesse a delle terminazioni nervose. Il nostro cervello "percepisce" lo stimolo provieniente da un particolare gruppo di cellule inner più il gruppo di cellule outer di una specifica regione e lo associa ad una ed una sola frequenza.
Un ultima cosa. Perchè alcuni suoni danno una sensazione piacevole (consonante) ed altri no?
Il tutto dipende dalla forma spiraliforme della coclea. I suoni si spostano lungo la spirale a distanze ed altezze diverse.
La geometria della coclea permette che suoni con frequenze che sono in rapporti specifici (per esempio quelle ad un numero intero di ottave di distanza) si distribuiscano lungo i raggi della spirale. I raggi si "spostano" in senso orario man mano che le frequenze si vanno più alte, ma l'allineamento tra suoni con determinati rapporti è molto regolare. Inoltre, ogni nota, ovviamente, sarà rappresentata da più raggi (per quanto abbiamo detto prima, ogi suono è costituito da più onde sinusoidali). Maggiore è l'allineamento tra i raggi che rappresentano due note, maggiore è la sensazione di consonanza. Per esempio, un Do ed un Mi hanno un raggio comune e stanno bene se percepiti simultaneamente. Un Do e il Do ad un'ottava di distanza hanno tutti i raggi in comune, e sono molto piacevoli da udire simultaneamente, anche se distribuiti ad altezze diverse. Un Do ed un Si non hanno raggi comuni e danno un effetto dissonante se suonati insieme.
That's it!
Spero di non avervi annoiato troppo. Io mi sono divertita un sacco a scrivere.
Parliamo di acustica e del modo in cui il nostro apparato uditivo analizzi i suoni e ci permetta di discriminare non solo un rumore da un suono, ma suoni diversi o, ancora, stesse note emesse da strumenti diversi.
Cominciamo da qualche nozione fisica sui suoni.
Il suono è un onda che possiede almeno tre caratteristiche fondamentali: intensità, frequenza, timbro.
L'intensità è l'energia associata ad un suono, che ci permette di classificare i suoni in forti e deboli.
La frequenza è il numero di oscillazioni che l'onda sonora compie in un secondo. Ad ogni frequenza corrispondono note diverse. Per esempio il 131 Hz corrisponde al Do che si trova un'ottava al di sotto dell'ottava centrale su una tastiera, 1046 al Do che si trova un'ottava sopra. 440 Hz è una frequenza importante per accordare qualunque strumento e corrisponde ad un La.
Inoltre, come prevedibile da quanto ho appena scritto, a frequenze alte corrispondono suoni acuti, a frequenze basse suoni gravi.
In realtà, i suoni che percepiamo non sono puri, cioè costituiti da una singola frequenza, ma da frequenze diverse, in rapporti ben definiti (le armoniche) e di intensità variabile. Insomma, il Do di un pianoforte non può essere rappresentato da una sinusoide, ma dalla somma di sinusoidi diverse. E il l'onda che rappresenta Do emesso da una chitarra non ha la sstessa forma di quello di un violino o di un sax.
Penso di non aver aggiunto molte informazioni (anzi) alla vostra conoscenza musicale. Magari posso fare meglio con l'anatomia dell'orecchio.
La parte più affascinante del nostro apparato uditivo è la coclea.
Essa è una piccola chiocciola (gli anatomici non hanno molta fantasia), contenuta in una cavità ossea. E' delimitata da una struttura membranosa piuttosto elastica, che, intenrnamente, presenta delle specie di rampe, che la suddividono in tre scale: la timpanica, la media e la vestibolare.
Essa è connessa con la catena di ossicini (incudine, martello e staffa) che sono messi in vibrazione dal timpano.
La scala media contiene del liquido, l'endolinfa, mentre le scale timpanica e vestibolare contengono perilinfa (l'importanza di questa differenza risiede nella diversa composizione ionica dei due liquidi, in cui non entreremo in dettaglio).

Sulla membrana basilare ci sono delle simpatiche cellule capellute (di potrebbe tradurre così il termine Hairy Cells), che fanno fluire ioni quando deflettono i loro capelli in un senso e limitano l'influsso quando si piegano nel senso opposto. Questo corrisponde rispettivamente ad un aumento ed ad una diminuizione di corrente all'interno delle cellule recettoriali. Tale potenziale graduato (che è tanto più intenso quanto maggiore è la deflessione dei capelli), induce il rilascio di neurotrasmettitori all'interfaccia tra cellule capellute e terminazioni del nervo acustico, che induce l'insorgenza di potenziali d'azione.
Una seconda osservazione che dobbiamo tenere presente è che esistono cellule Inner ed Outer, poi capiremo perchè.
Ora, il potenziale d'azione è un'onda stereotipata, che dura 1 ms, e varia da -80 mV a +120 mV.
Esso è generato, come forse ho già detto, dall'apertura di conduttanze sulla membrana dei neuroni. Ha una forma, un andamento caratteristico, perchè deve essere univoco e riproducibile, chiaro e ben distinto da ogni rumore di fondo, rigenerabile e non attenuabile.
Insomma, in sistema nervoso ha deciso di utilizzare un segnale digitale e non analogico per essere certo che le informazioni non si eprdano e non si confondano. Questo, ovviamente, a scapito di un alfabeto complesso e modulabile. Un po' come usare un lettore mp3 invece dei dischi in vinile.
Dopo questo preambolo un po' complesso, arriviamo al punto.
Se abbiamo un alfabeto semplice, digitale, possiamo solo codificare poche informazioni. In particolare, utilizzando un potenziale stereotipato,l'unica cosa che le cellule possono fare è variare la frequnza di spiking e neanche di molto (c'è un limite massimo di scarica, che corrisponde alla frequenza di 200Hz).
Il problema è il seguene: come possiamo codificare 3 informazioni in questo modo?
E, inoltre, come possiamo coprire tutta la gamma delle informazioni che giungono alla coclea?
Dunque, il nostro orecchio ha deciso di connettere ogni cellula a più terminazioni nervose (10 per ogni Inner).
Per frequenze tra 20 e 200 Hz, le cellule capellute di deflettono con frequenza analoga alla frequenza dell'onda, da una parte e dall'altra, alternativamente. A seconda dell'intensità dell'onda la deflessione sarà più o meno importante e il flusso di ioni più o meno ingente. Il potenziale graduato nelle cellule capellute indurrà variazioni di corrente tanto più grandi quanto più la deflessione è grande.
Alcune delle terminazioni nervose connesse con le cellule capellute spareranno con frequnza identica a quella delle hairy cells, altre con frequenza tanto maggiore quanto più intenso è il potenziale graduato.
Ma se il suono non è puro?
L'orecchio ha elaborato in parallelo al meccanismo appena descritto, che può essere definito time code, un place code.
In sostanza, la coclea funziona come un insieme di filtri, un analizzatore di Fourier, che scompone qualunque onda in un insieme di suoni puri di frequenza definita.
Frequenze diverse raggingono punti diversi della coclea, deformandone la membrana. Insomma, ciascun punto subisce una deformazione massima per una determinata frequenza, con i suoni acuti che deformano massimamente la porzione basale, i suoni gravi quella apicale.
Questo permette di avvertire la differenza tra un pianoforte ed una chitarra, per frequenze fino a 200 Hz.
E per frequenze superiori?
Qui entrano in gioco le cellule outer, che amplificano la deformazione della membrana basale per frequenze specifiche, con un meccanismo diverso da quello delle inner, che permette loro di contrarsi a frequnze elevatissime (sono delle specie di piccole molle che si allungano e si accorsiano). Anche le outer sono connesse a delle terminazioni nervose. Il nostro cervello "percepisce" lo stimolo provieniente da un particolare gruppo di cellule inner più il gruppo di cellule outer di una specifica regione e lo associa ad una ed una sola frequenza.
Un ultima cosa. Perchè alcuni suoni danno una sensazione piacevole (consonante) ed altri no?
Il tutto dipende dalla forma spiraliforme della coclea. I suoni si spostano lungo la spirale a distanze ed altezze diverse.
La geometria della coclea permette che suoni con frequenze che sono in rapporti specifici (per esempio quelle ad un numero intero di ottave di distanza) si distribuiscano lungo i raggi della spirale. I raggi si "spostano" in senso orario man mano che le frequenze si vanno più alte, ma l'allineamento tra suoni con determinati rapporti è molto regolare. Inoltre, ogni nota, ovviamente, sarà rappresentata da più raggi (per quanto abbiamo detto prima, ogi suono è costituito da più onde sinusoidali). Maggiore è l'allineamento tra i raggi che rappresentano due note, maggiore è la sensazione di consonanza. Per esempio, un Do ed un Mi hanno un raggio comune e stanno bene se percepiti simultaneamente. Un Do e il Do ad un'ottava di distanza hanno tutti i raggi in comune, e sono molto piacevoli da udire simultaneamente, anche se distribuiti ad altezze diverse. Un Do ed un Si non hanno raggi comuni e danno un effetto dissonante se suonati insieme.
That's it!
Spero di non avervi annoiato troppo. Io mi sono divertita un sacco a scrivere.
posted by raraavis at 9:41 AM
![]()





2 Comments:
Pur senza particolari conoscenze mediche, la teoria musicale basata su questi presupposti acustici è definita da molto tempo. Per es. http://euromusicology.cs.uu.nl:6334/dynaweb/tmiweb/z/zarih58/
cioè le celebri Istituzioni Harmoniche di Zarlino.
Inoltre, una cosa è l'acustica e un'altra e la musica. Non si può fare musica solo con le consonanze, sarebbe estremamente riduttivo. Tanto per tornare all'esempio Do-Si (7a maggiore) è dissonanza, ma se preparata funziona eccome. A questo punto non so se la cosa sia spiegabile acusticamente quanto piuttosto psico-acusticamente.
Secondariamente, il sistema temperato è tutto basato su ottave perfette MA quinte imperfette (temperate) per permettere l'utilizzo di qualsivoglia tonalità. Quella che generalmente si ascolta è quindi musica acusticamente non pura, perché le consonanze di quinta de facto non sono tali. Sta di fatto che funziona egregiamente lo stesso.
Non mi sono spiegata bene.
Volevo dire che l'acustica ha basi fisiologiche (leggi fisiche "usate" da strutture anatomiche), ma è solo ed esclusivamente il primo livello di elborazione.
Il giunge al cervello attraverso numerosi nuclei e stazioni, dove viene elaborato. A livello centrale, poi, esso attiva numerose aree, olre a quella acustica.
Questi ulteriori steps vengono analizzati, studiati e, quando possibile, spiegati dalla psico-acustica.
La mia era solo un'introduzione al problema, non certo una trattazione sistematica, con la pretesa di esaurire un argomento di cui, tra l'altro, è presuntuoso parlare solo in termini razionali.
Anyway, mi fa molto piacere che tu legga e commenti il mio blog. Grazie.
Post a Comment
<< Home